
Resilience when using Google Kubernetes in Autopilot mode

Please note that this blog post has been originally published on blog.musicglue.tech company blog.
…or a little story about how everything isn’t provided by default.
The current state of affairs
I will be describing an example app – dockerised, stateless and more-or-less follows the Twelve-Factor App methodology – deployed on a Kubernetes cluster. Let’s say an e-commerce store, although it doesn’t matter that much in this particular note. The cluster itself is running in autopilot mode, which means Google provisions and de-provisions nodes for us, while we’re paying only for the resources we’re using, but we’re also giving up administrative control of the nodes.
How we can guarantee resilience when using GKE in autopilot mode
When using GKE autopilot cluster in regional mode, it gives you resilience (as in: control plane access) out of the box. Since we don’t control nodes, and the the control plane is replicated, then we expect the same for our workloads. However when using default pod settings and deployment, you can’t guarantee that your app (think: stuff deployed on worker nodes) will be available at any given time.
In this post I will showcase three real-life scenarios where your app could end up unexpectedly being offline, while still obeying all the requirements you explicitly specified in your K8s manifests, and how you can protect your deployment from those events.
What are we working with?
We’re deploying an e-commerce application as a single container (along with other services omitted for clarity). We’re deploying two copies of the app (two replicas), in order to ensure high availability. Just like you would normally do in an on-prem environment.
In a nutshell, our deployment is two pods, each consisting of a single container spread somewhere in the K8s cluster.
Scenario A - Raiders of the Lost Node
Your cluster has nodes A, B and C (you can’t see them, since it’s hidden from you, but they are there - you can verify with kubectl get nodes). You’re deploying two replicas of the app for resiliency. However, it happens that they are both deployed on node A.
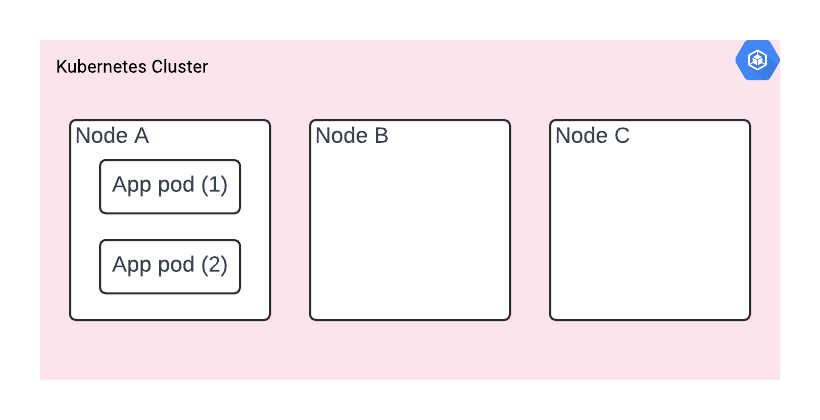
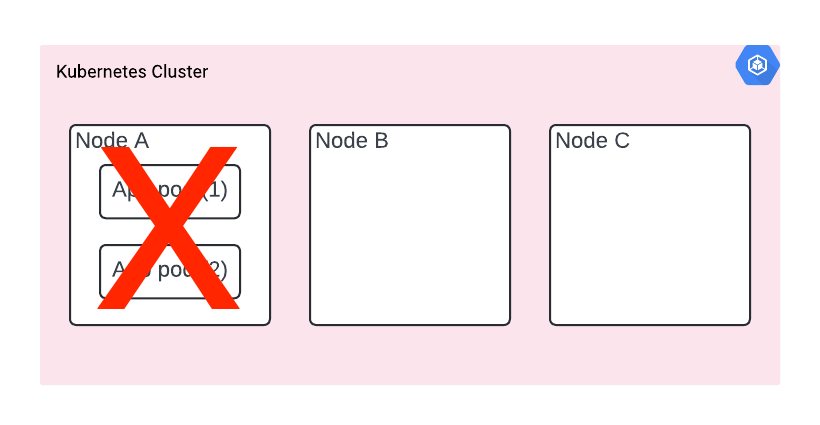
Then node A goes down for any reason. If we’re lucky and it’s planned, our app is going to receive SIGTERM and K8s will start spinning it up on a second node. Maybe we get away with no downtime.
But if it’s a crash or hardware failure (yes, there is real hardware behind the cloud!) then you’re suddenly without any copy of a running app.
The solution? You need to specify pod anti-affinity. It’s a very specific instruction given to the scheduler. It means pods are steered away from each other and run on separate nodes, a bit like magnets repelling each other. By using topologyKey: “kubernetes.io/hostname”, we’re specifying that we want the hostname as the discriminator, which means the pods will be spread across available nodes.
However, since we’re using preferredDuringSchedulingIgnoredDuringExecution, it means this isn’t a hard requirement. If for any reason, e.g. GCP is currently running out of nodes, K8s won’t be able to fulfil the spec, K8s would still run two copies of our app.
The opposite policy would be requiredDuringSchedulingIgnoredDuringExecution. Please note, that the hard requirement might cause your pods to be stuck in unschedulable state. If the scheduler is unable to find suitable nodes, it will simply refuse to run them. In autopilot’s case, it will probably mean that the cluster needs to scale in order to have new nodes available, which will take extra time and may be inconvenient at the given time.
As implied by the “ignoredDuringExecution” suffix, these policies have no effect on a pod’s runtime lifecycle. Hence your pods may still end up on same node in some unlikely turn of events.
spec:
template:
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- unit
topologyKey: “kubernetes.io/hostname”
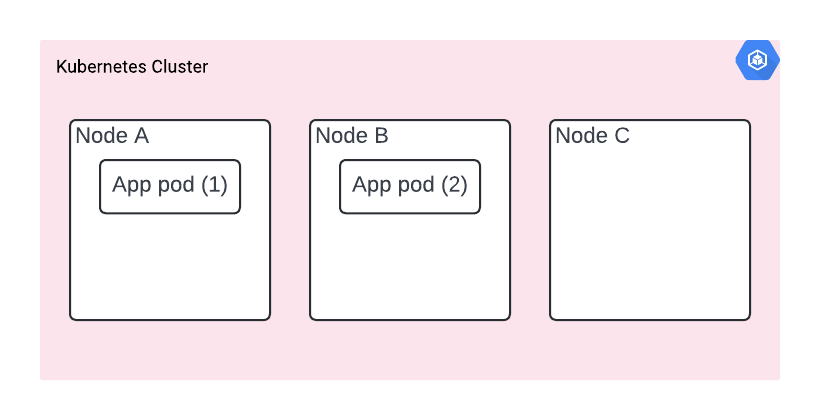
Scenario B - The Zone of Doom
You deployed your app with pod anti-affinity and it’s now deployed on nodes A and B. However, it turns out they are both in the same zone.
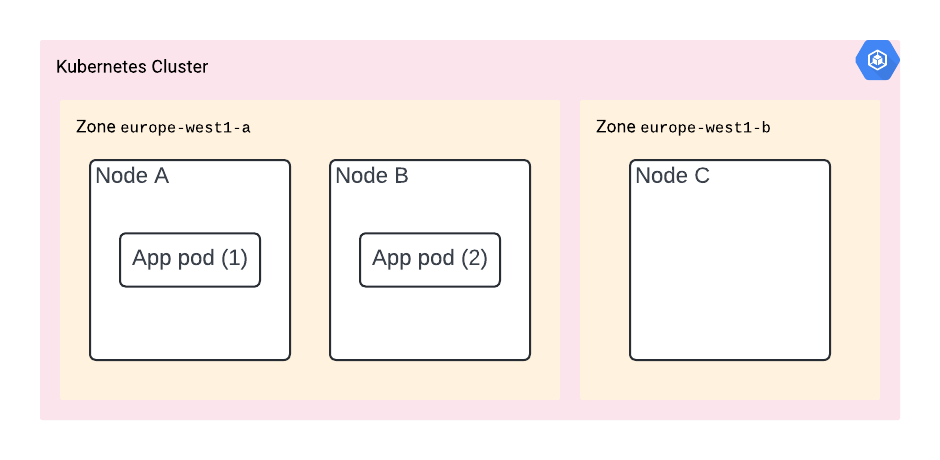
Should that zone go down, then so does your app.
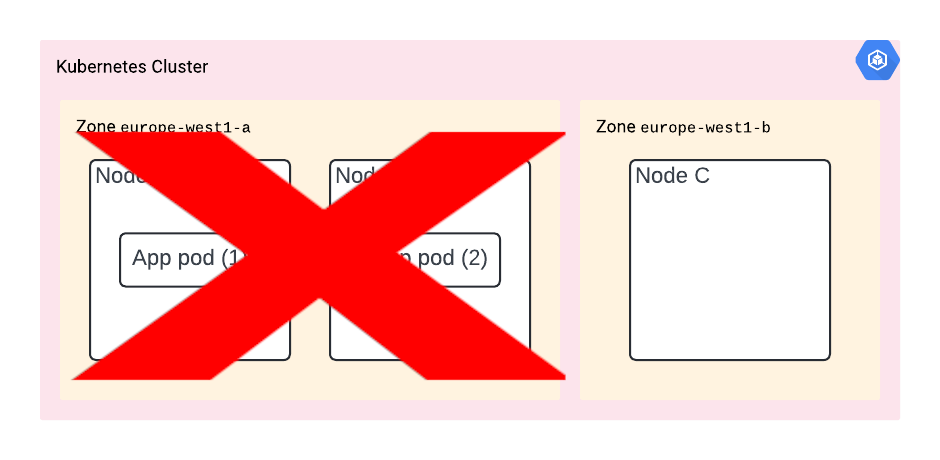
You’re out of luck again.
The solution? You need to deploy your app in multiple zones. You can do it by using a regional cluster – which is the only cluster type available when using GKE in autopilot mode, and specifying the topologyKey in your deployment’s podAntiAffinity spec:
spec:
template:
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- unit
topologyKey: topology.kubernetes.io/zone
If you need more control and options (which are unsuitable to express in affinity terms) there is also another configuration called topologySpreadConstraints. You can find the motivations behind it in the docs and on the proposal when it was introduced.
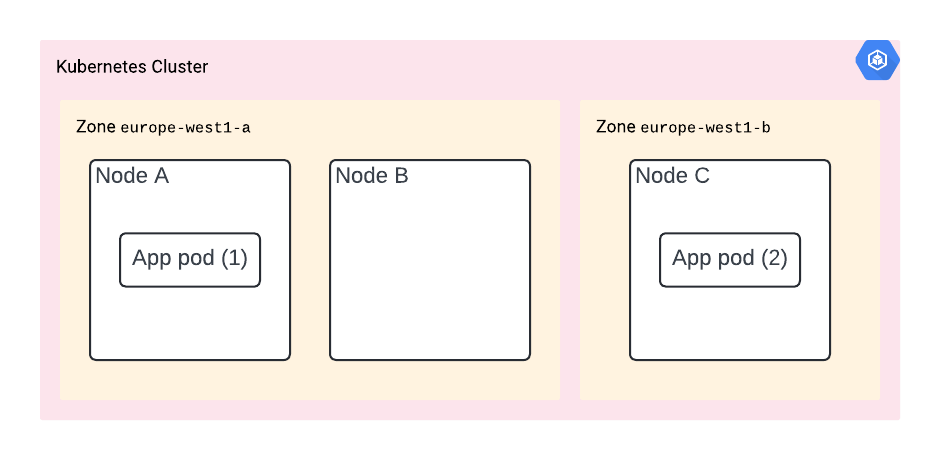
Scenario C - The Last Upgrade
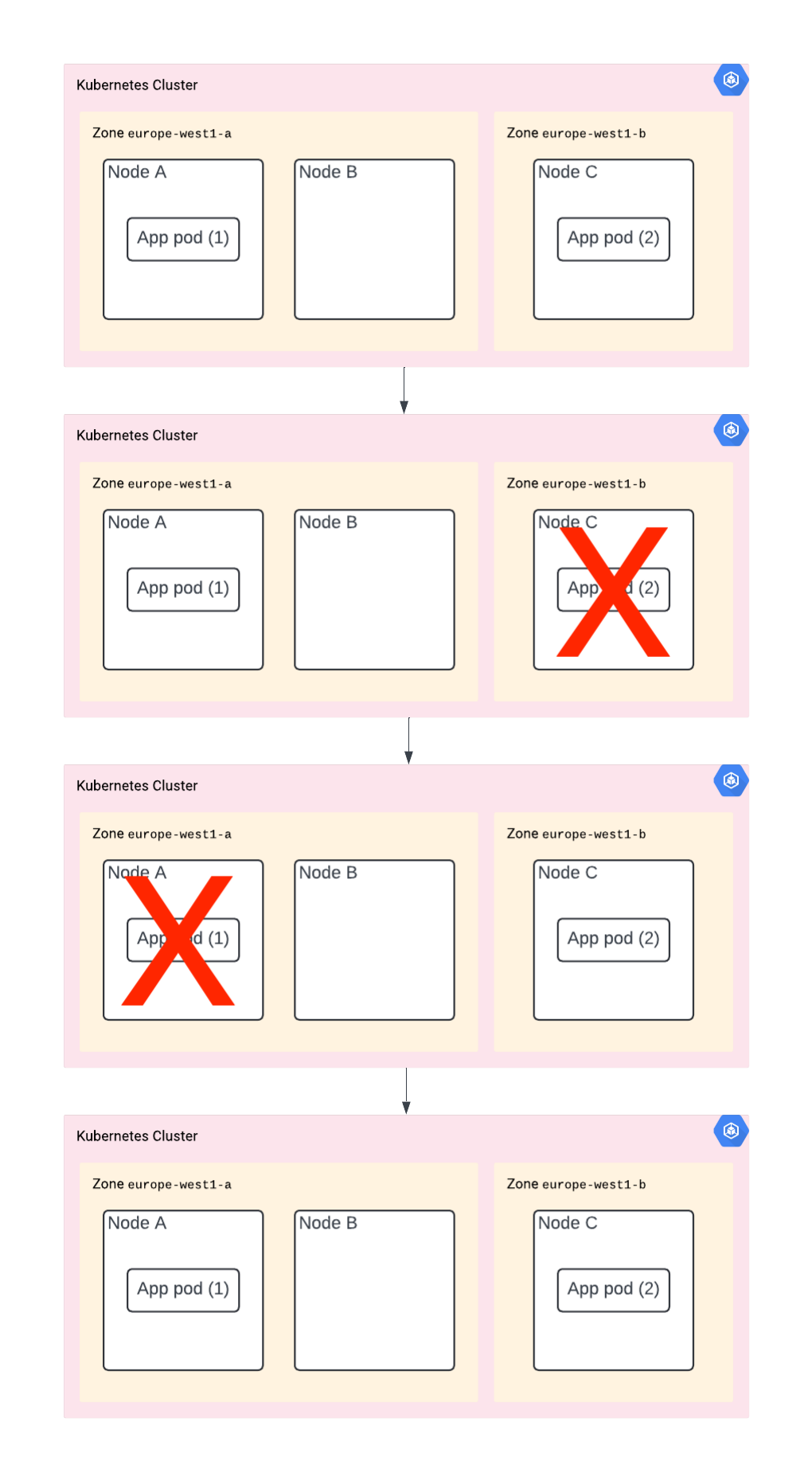
You did all of the above. However, now the K8s control plane is doing node upgrades. And – you guessed it – node A and C are going to be upgraded at the same time. In other words, your app is going to be down. Again, no luck.
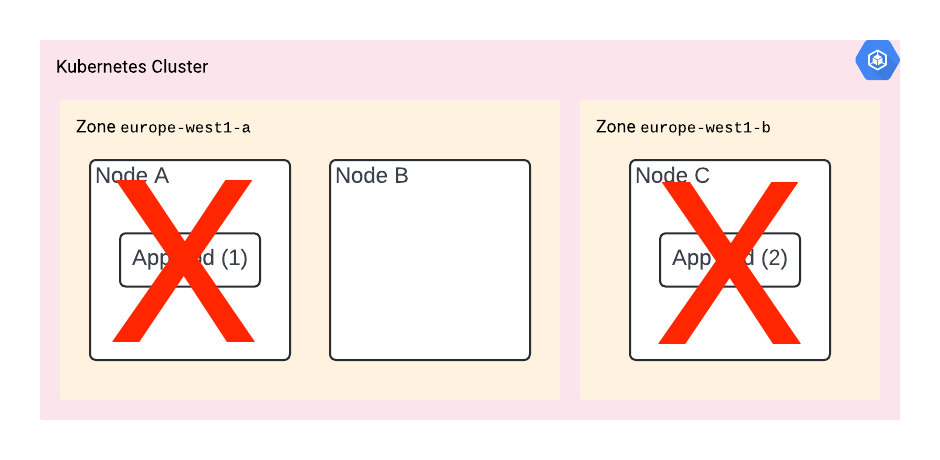
The solution? You need to use PodDisruptionBudget to limit how many pods can be down at the same time, or at least how many are required to be up.
Example:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: unit-pdb
spec:
minAvailable: 1
selector:
matchLabels:
app: unit
Although it depends on the situation and the decisions by the scheduler, when running it may look like this:
Conclusion
I hope you find these additions to your toolbox useful and you never again made a mistake of having HA pods setup, which in case of failure, turns out to be not-HA at all.
If you want to read more, here are some links that might be useful to you:
Deploying Elixir is a reader-supported publication. To receive new posts and support my work:
or